機械学習を用いた受託開発を行っている会社で営業とエンジニアをしている江藤(@as00812145)といいます。
昨今ディープラーニングや機械学習が叫ばれて久しいですが、言葉だけが独り歩きして、機械学習が具体的に何なのか?
機械学習の何が利用されてサービスが作られているのか、包括的に概要を把握するのは難しいと思います。
そういった、ふわっとしたイメージをできるだめ具体的に固めたい人のために今回は、機械学習の概要から、実際の使われ方などを図を交えて解説していきます。
機械学習とは
はじめにそもそも機械学習にとはなんぞや?ということを解説していきます。
機械学習とはたくさんのデータをもとにして、パターンや特徴を見つけ出して、それらを自動的に判別するor予測するような機構を持たせるための技術です。
機械学習に共通する考え方は、データを入力したら結果を予測する機構(判別機という)を作ろうというものです。
そして、入力されるデータは何らかの規則性(分布など)があるはずだから、その規則性を発見するために、既存のデータを活用して学習させて、その規則性に近似しようという考え方があります。
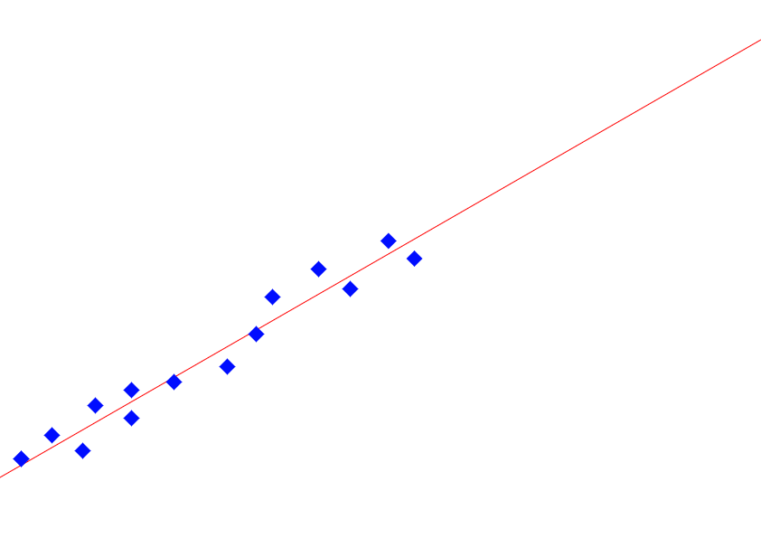
ちょうど図のような感じで、青い点が私達が把握しているデータで、本当の把握したい規則性は赤い曲線だと思ってください。
この青い点の量が多くなるほど、赤い曲線に近づいて行くことがわかります。
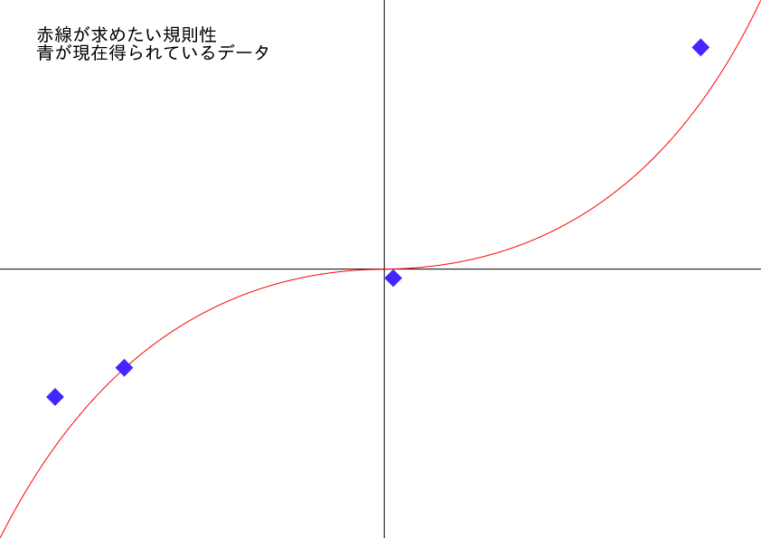
実際には、こんな単純な形ではわからないのですが、ようは、数学の公式みたいに、必ず答えが出る方程式を見つけるor近似するために、データの物量にものを言わせて探索していくんですね。
機会学習のカテゴリー
機械学習の大まかな考え方がわかったところで、具体的にどういった予測の仕方があるのかを解説していきます。
大まかな関係図を使って解説していきたいと思います。
またこれから、機械学習によってできた何らかを判断する機構のことを判別機をよびます。断じてAIや人工知能ではありません。
それらはまた別の意味やそもそも定義が言ってる人で違うことがあるので、誤解を避けるため判別機と呼称します。
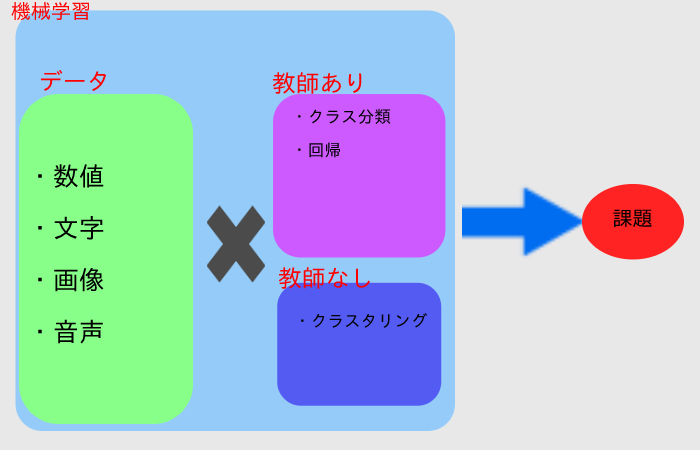
基本的には手元にデータがあって、そのデータからどういった形で活用するかということで、最終的に作り出す判別機の種類と作り出す方法を選びます。
そして、この判別機の結果を用いて実際の問題を解決していくんですね。
今回は判別機の生成方法についてはふれません。非常に種類が多く混乱を招く可能性があるので、また機会があれば別個で解説していきたいと思います。
なのでこれからは判別機の種類のみを解説していきます。
教師あり
教師ありとはデータを予測する前に、事前にデータを与えておき、それをもとに学習して、データの予測や分類をおこないます。
このアプローチのおかけで、目的に応じた十分量のデータさえあれば簡単に学習が行うことができ、特定の目的に特化しているので、比較的簡単に導入していくことができるので、
今機械学習が使われているサービスはだいたい教師あり学習になっています。
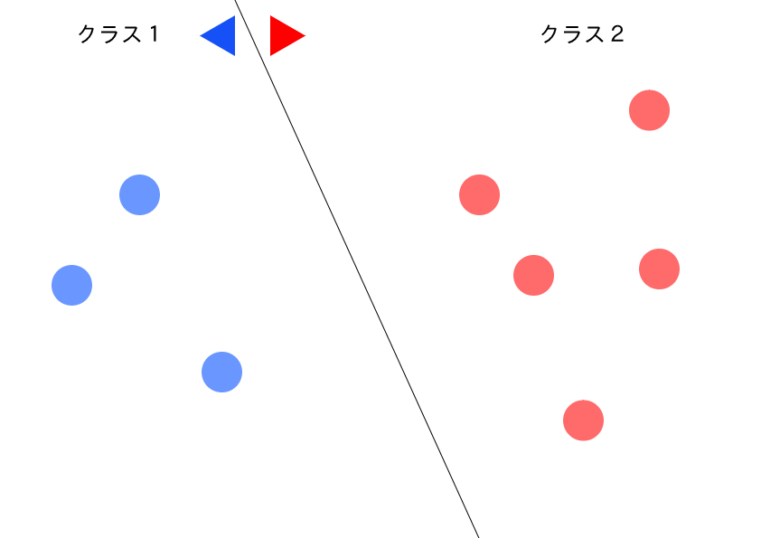
クラス分類
クラス分類は予め、手元にあるデータにラベルを貼っておき、そのラベルのものに該当するかどうかをという形でデータを判別していきます。
例えば、写真に写っている人が笑っているかどうかという形で判別したい場合。
写真には 「笑っている」 「笑っていない」と2つの状態(ラベル)があるわけです。
これを機械学習を使ってつかってどちらの状態に当てはまっているのかを判別していくのです。
回帰
回帰は学校で習った関数のように数値的に観測して判別していきます。
例えば、1年間の需要予測のを機械学習で考えてみましょう。今回は具体的に雑貨屋の物品の在庫の仕入れのためにどれくらい需要があるかを予測してみるとしましょう。その場合に、月にどのくらい、といった形で具体的な数値で予測していきます。
先程ののクラス分類と違って、回帰は未来の物事を数値的に予測するときに使っていきます。
教師なし
先程の教師ありとは違い、手元のデータの中から自分が決めた目的に向かって分析していくのではなく、データにどういったパターンや特徴があるかを知るために使います。
なので単体で利用するというより、これを利用して教師あり学習の形へ持っていく、という形で利用されることが多いです。
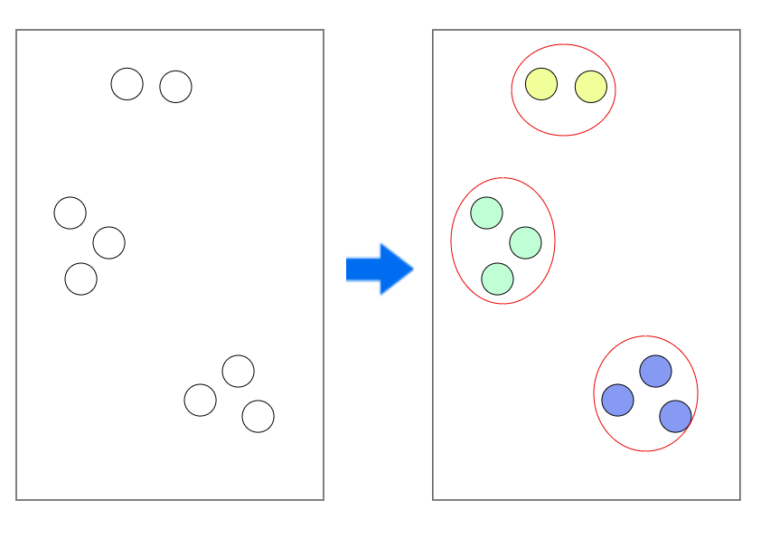
クラスタリング
クラスタリングは手元にあるデータの情報をから大まですかなクラスタ(塊)を判別する手法です。
ただ、先程も行ったとおり、クラスタ単体だとあまり実際の作業では役に立ちません。
クラスタリングはデータの特徴を知るために使われるので、正解、不正解を決めるのがそもそも難しい(転売屋の人を探索するとなった場合にどんな人が転売屋なのかが決めづらいなど)のときに
データを大まかに分類して、そこから特徴を洗い出して教師データの特徴にするのです。
ニューラルネット・ディープラーニング

現在のAIブームを引き起こしたディープラーニングとその基礎であるニューラルネットについても簡単にふれておきます。
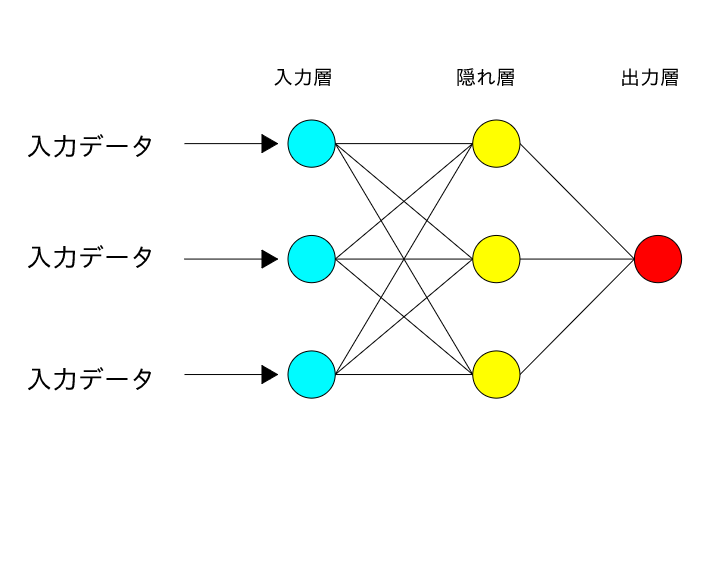
ニューラルネットは人間の脳の細胞(ニューロン)をモデルとして作られた判別方法です。
一つの入力を受け取ってそれが条件を満たしているかどうかを判別し、満たしていれば次のニューロンへその値を伝達(発火)
満たしていなければ何もしない。こうして、発火していった情報を最後に出力してその結果から判別していきます。
また、ニューラルネット自体は先程の、 クラス分類と回帰の両方で使うことができます。
この複数の層の機構をすごく深くしたのが、ディープラーニングとなります。
ディープラーニング自体の高層は結構昔からあったのですが、層が多すぎると実践の場でちゃんと機能しないという性質がありました。
そして最近、DropOutというランダムに次のニューロンへの伝達を停止する手法を行ったら、なぜかちゃんと機能するようになっただけでなく、画像や音声などの領域で実用的に機械学習を使ってサービスを組めるレベルの精度となり現在のAIブームに繋がっています。
ちなみに、なぜDropOutを適用したら、実践的に役に立つようになったかは実はまだ学会でも解明されていません。
そんな、実践ありきの技術のせいか、ディープラーニングの領域は職人技のようにそのデータサイエンティストの肌感覚で作らていることが多いです。
まとめ
機械学習のみだと、やたらニューラルネットやディープラーニングが注目されがちですが、
それらはあくまで手法や手順の一端であって、本質ではありません。
正しく実践の場で扱う場合にはディープラーニングの他にどういった解決方法があるのかが重要にもなってくるので、機械学習の概要やディープラーニングがどこに位置するのかということが把握できるになっていれば幸いです。