
昨今、機械学習の流行とともに、Webサイトからデータを収集するスクレイピングの技術が必要とされています。
しかし、スクレイピングといっても、「どのフレームワークで開発すべきか」や「スクレイピングの注意事項」といった部分がわかりにくく、困っている人もいるでしょう。
そこで今回は、初心者の方に向けたPythonを使用したスクレイピングの方法と応用方法について紹介していきます。
AIやデータサイエンスを学びたくてPythonを学び始めたけど
「独学ではやっぱり限界がある」
と不安を感じた方にオススメしたいのが、Aidemy Premium Plan。
AIに関する幅広い種類の講座や徹底したコーチング指導が特徴です!

実務を見据えてPythonをがっつり学習していきたい方は、まずは無料の「オンライン相談」に参加してみてください。
また、Aidemy Premium Planのメリットやデメリットなどについては、以下の記事も参考にしてください。
Aidemy(アイデミー)の評判と口コミまとめ!受講したほうがいい理由を紹介
Pythonを使ったスクレイピングの前に:事前知識
初めに、Pythonを用いたスクレイピングの実装を行う前に、「スクレイピング」とはそもそも何なのか、について説明します。
もし「そんなの知ってるよ!」という方がいましたら、<Pythonを使ったスクレイピングの方法>まで読み飛ばしてください。
スクレイピングとは
スクレイピングとは、WebページのHTMLから必要な情報を取得することを指します。
近年では、機械学習を行う際に膨大なデータ数が必要となることから、手動では効率が悪いので、Pythonなどでプログラムを書いて自動化をする技術が重要になってきています。
例えば、競馬の情報をスクレイピングで集めたいとなった場合は、競馬の戦績や馬の情報などの情報が保存されているウェブページを探して、そのページ内の情報をプログラムを用いて自動で収集していくという手順になります。
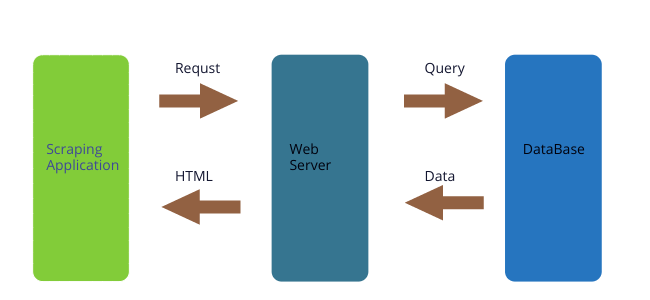
スクレイピングは特定のURLにアクセス、つまりhttpリクエストから帰ってきたHTMLから情報を抽出します。なので、上の図のように、最終的に手元に帰ってくるのはHTMLとなります。
スクレイピングを行う際の注意点
スクレイピングを行う際に気をつけなければならない注意点があります。
それは、収集速度を追求したスクレイピングは、収集先のウェブページのサーバーにひどい負荷を書けることになるという点です。
そのような行為は最悪の場合、威力業務妨害などで訴えられる可能性があります。
また、サーバーに負荷がかかること・著作権侵害の観点から、スクレイピングを禁止しているサイトも多くあります。
スクレイピングが禁止されているサイトについては、サイトの利用規約に記されております。
スクレイピングを行う際は、まず対象のサイトがスクレイピングを禁止していないかを確かめてから、Webサイトのサーバーに配慮しつつ行いましょう。
一般的なスクレイピングの方法
一般的なスクレイピングは、HTTPリクエストを投げたり、HTMLから情報を抜いたりなど、複数の要素で構成されています。
そのため、スクレイピングを行う際は、複数のライブラリを使い分けて、且つ対象のページに合わせて作らなければなりません。
一般的には、以下のライブラリの組み合わせが有名です。
| Requests | WebページのHTML情報を取得するライブラリ |
| Beautiful Soup | HTMLの情報を抽出するライブラリ |
| Selenium | ログインなどブラウザ上の操作が必要なページのデータ取得を可能にするライブラリ |
これらを使い分けるだけでも煩雑ですが、条件によっては、「ページを巡回し」「データをDBにためる」などの要素が絡むと、実装のみでなく設計も重要になってきて、開発するだけでも結構な時間を使ってしまいます。
この方法は初心者には向きません。
Pythonを使ったスクレイピングの方法
ここからは、Pythonを使ったスクレイピングを実際のコードと共に解説していきます。
pipenvの環境がない方は、こちらを参考にインストールしてください。
【初心者向け】Pythonのインストールから環境構築までをわかりやすく解説!
初心者のスクレイピングに適したPythonフレームワーク: Scrapy
そこで、今回紹介するPythonのフレームワークが、Scrapyです。
Scrapyは、先程解説したデータの取得から抽出までを簡単に設定できるスクレイピングフレームワークです。
さらに、Scrapyの基本構造をもとにカスタマイズしていくことで、設計などを気にせずにスクレイピングツールを作成することができます。
https://cdn-ak.f.st-hatena.com/images/fotolife/t/todays_mitsui/20160924/20160924231058.png

Install
まずは、Scrapyをインストールしましょう。
[code language=”shell”] pip install scrapy [/code]
[code language=”shell”] conda install scrapy [/code]
プロジェクト作成
Scrapyには、起動に必要な機能をコマンドから生成する機能があります。
[code language=”shell”] scrapy startproject <プロジェクト名> [/code]
これにより以下の構造が生成されます。
[code language=”bash”]
testProject/
├── scrapy.cfg
└── testProject
├── __init__.py
├── items.py // スクレイピングする対象の変数を作成する
├── middlewares.py //
├── pipelines.py //
├── __pycache__
├── settings.py // クローリングやダウンロードの設定を行う
└── spiders // ここに自分のスクレイピングのスクリプトを作成する
├── __init__.py
└── __pycache__
[/code]
Scrapyを使用したPythonスクレイピングの実装例
さて、実装例です。
「特定のドメインを持つウェブサイトを巡回(クローリング)してスクレイピングしていく」という実装をします。
今回は、Yahooニュースの情報をスクレイピングしたいと思います。
https://news.yahoo.co.jp/
取得する情報の決定
まずは、どの情報を取得するのかを決定しましょう。
testProject/items.pyを開き、そこに実装していきます。
Scrapyでは、 Fieldというクラスから、変数を作成して収集した情報を格納する変数を作ります。
[code language=”python”]
import scrapy
class TestprojectItem(scrapy.Item):
# define the fields for your item here like:の
name = scrapy.Field()
pass
[/code]
クローリング
巡回(クローリング)について実装していきます。
ここで必要なものは、
- クローリングスタート地点
- クローリングのルールの決定
- クローリングの対象
の3つです。
今回はシンプルな構造のため、クローリングのスタート地点のみで実装出来るものを行います。
[code language=”python”]
# -*- coding: utf-8 -*-
import scrapy
from testProject.items import TestprojectItem
class TestSpider(scrapy.Spider):
name = “test_spider”
start_urls = [
“https://news.yahoo.co.jp/” // これがクローリングのスタート地点のURL
]
def parse(self, response):
“””
ページの巡回経路を記述する関数。
:return: None
“””
news_list = response.xpath(“//body//ul[@class=’toptopics_list’]//li”)
self.logger.critical(news_list)
for news in news_list:
self.logger.critical(news.xpath(“a/@href”).extract())
# ニュースのリンクから情報からもう一度リクエストを投げる
yield scrapy.Request(url=news.xpath(“a/@href”).extract()[0],callback=self.parse_page)
[/code]
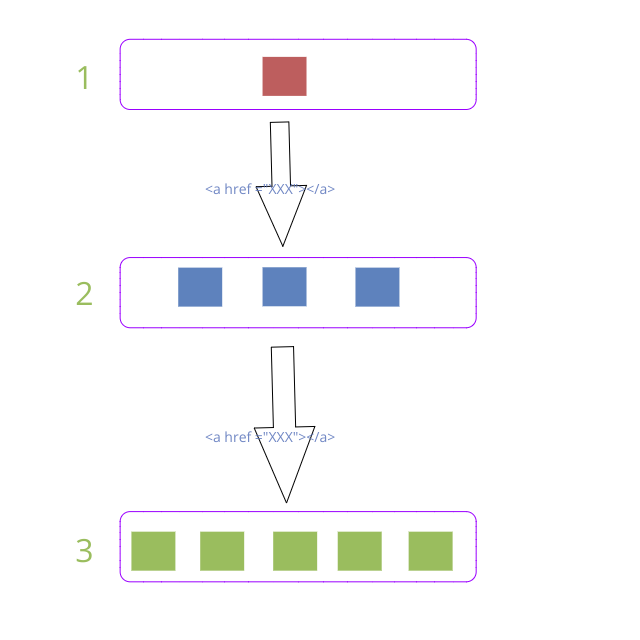
スクレイピング
次は、情報取得(スクレイピング)です。
先程の図のように、リクエストを投げて帰ってきたHTMLから情報を取得します。
Scrapyの場合は css selector と xpathが使えます。
今回はあまり知られていないxpathを用いて実装していきましょう。
-
- 要素の指定
`//h1`
-
- 要素のテキスト
`//p/text()`
-
- クラス名などのプロパティを指定
`//a[@id=”test”]`
-
- 兄弟要素の特定の物だけを指定
//li[1]/text()
これさえできていれば、大抵のデータ抽出は問題ないでしょう。
その他の記法については、以下を参照してください。
実装例
/TestProject/spiders/以下に testSpider.pyというファイルを作り以下のコードを書いていきましょう。
[code language=”python”]
# -*- coding: utf-8 -*-
import scrapy
from testProject.items import TestprojectItem
class TestSpider(scrapy.Spider):
name = “test_spider” # スパイダーの名前(scrapyを実行する際に必要なスクリプトの名前のようなもの)
start_urls = [
“https://news.yahoo.co.jp/” # どの地点からクローリングを始めるかの指定
]
def parse(self, response):
“””
ページの巡回経路を記述する関数。
:return: None
“””
news_list = response.xpath(“//body//ul[@class=’toptopics_list’]//li”)
for news in news_list:
self.logger.critical(news.xpath(“a/@href”).extract())
yield scrapy.Request(url=news.xpath(“a/@href”).extract()[0],callback=self.parse_page)
def parse_page(self, response):
item = TestprojectItem()
item[“title”] = response.xpath(“//h2[@class=’tpcNews_title’]/text()”).extract()
item[“summary”] = response.xpath(“//p[@class=’tpcNews_summary’]/text()”).extract()
yield item
[/code]
これの部分は少々ややこしいので、詳しく解説していきます。
流れとしては以下のサイクルを回しています。
* ニュースリストのHTML情報を抽出
* ニュースリストの部分からaタグのリンク先のURL情報を取得
* 取得したURLをもとにもう一度リクエストを投げ、どのように抽出するかをcallbackで指定する
* 情報を取得してitemに格納して戻り値として返す
Scrapyは、スクレイピングを実行すると指定したURLにリクエスト投げて、その結果がレスポンスとして帰ってきます。
これは 11行目のparseの関数の第二引数に格納されます。(以下レスポンスオブジェクトと呼びます)
このレスポンスオブジェクトには指定したURLのレスポンス、つまりHTMLがbodyという変数として格納されていて、
それに対して抽出を行う関数が実装されています。
今回はxpathを使用して抽出していますが、それに該当するのが、16~行目の部分です。
今回はニューズのリストの部分のリンクから飛んでその先の情報を取得しています。
16~19行目でニュースのリスト部分を取得して、そこから aタグのリンク先のURL情報を取得しています。
その取得したURLをもとに再度Requestを投げているのが、19行目です。
リクエストに対してどのように値を抽出するかの関数が21行目のparse_pageとなります。
実行
それでは、実行してみましょう
実行コマンドは、自身で実装したスクリプトの階層で以下のコマンドを実装します。
今回は確認しやすいようにcsvで吐いてみましょう。
[code language=”language=”]
scrapy runspider <スパイダーの名前> -o <ファイル名> -t <ファイルフォーマット>
[/code]
今回の場合だと、↓の感じになります。
[code language=”language=”]
cd testProject/spiders
scrapy runspider test_spider -o test.csv -t csv
[/code]
これで、
testProject/spiders
にcsvが生成されれば成功です。
debug
これで実行ができました。
しかし、毎回 HTMLの構造を見て、pythonにソースコードを書いて、結果を検証するというのは、非常に面倒です。
特に、得たい情報を抽出できているのか、それはxpathの問題なのかをチェックぐらいはチェックをしたいです。
そこで、scrapyのshellを使って検証しましょう。
shell の起動
[code language=”bash”]
scrapy shell
[/code]
URLの指定
[code language=”bash”]
fetch (<URL>)
[/code]
xpathで指定してみる
[code language=”bash”]
resposen.xpath(<xpath>).extract()
[/code]
これで結果を表示してみます。
設定
Scrapyはsetting.pyというものからデータを諸々の設定を行います。
例えば、クローリングのスピードや一回取得したページは無視するのかといったものです。
たいていの場合は、
[code language=”python”] <パラメーター名>: パラメータ[/code]
となっています。
今回は、一回のリクエストに数秒待つという処理を入れましょう。
setting.pyに
[code language=”python”]DOWNLOAD_DELAY: 2[/code]
の一行を加えましょう。
これで一つのページからデータをダウンロードした後2秒待つという設定になりました。
その他のパラメータの設定などは以下のページに一覧があるのでそこを参照してください。
https://docs.scrapy.org/en/latest/topics/settings.html
スクレイピングをしたいページがSPAやログインを必要とする場合
ここまでで基本的なスクレイピングが出来るようになったのですが、これだけでは不十分です。
javascruptを非同期でページをロードする構成のページ(SPA)やログインしないと見られないページにおいては、Scrapyだけでは完全な情報を取得することができないからです。
そこで、席ほど紹介したseleniumというライブラリを導入することで、ソースコードから直接フォームに値をいれてログインしたり、ロードボタンを押したりすることができようになるので、これを組み合わせて使いましょう。
selenium
seleniumは、ソースコードからブラウザを操作できるツールです。
公式サイト
- install
[code language=”shell”] pip install selenium [/code]
[code language=”shell”] conda install selenium [/code]
- setup
このツールは、コードを書いてブラウザを操作できる為、ログインフォームに自身の情報を入力してログインすることができます。
-
- 要素の取得
[code language=”python”]
driver.find_element_by_id(“id_name”) # HTMLのID名でデータを取得する
driver.find_element_by_class(“class_name”) # HTMLのID名でデータを取得する
[/code]
-
- もっと詳しい情報は
- フォーム入力
[code language=”python”]
form = driver.find_element_by_tag(“form”)
form.sendKey(“inout text”)
[/code]
- 送信
[code language=”python”]
form = driver.find_element_by_tag(“form”)
form.sendKey(“inout text”)
form.submit()
[/code]
ログイン処理のサンプル
[code language=”python”]
form = driver.find_element_by_tag(“form”)
email = driver.find_element_by_id(“email”) # email入力フォームの情報を取得
email.sendKey(“inout text”)
pass = driver.find_element_by_id(“password”) # password入力フォームの情報を取得
pass.sendKey(“inout text”)
form.submit() # 送信
[/code]
Scrapyとの連携
さてここで、ScrapyとSeleniumを連携させていきましょう。
Scrapyには、middlewareという特定の処理のタイミング(URLにリクエスト投げる前に、エラーが発生した時など)に別の処理を挟める機能があります。
今回はわかりやすくするため、一つのファイルに記述します。
[code language=”python”]
# -*- coding: utf-8 -*-
import scrapy
from testProject.items import TestprojectItem
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
class TestSpider(scrapy.Spider):
name = “test_spider”
start_urls = [
“https://news.yahoo.co.jp/”
]
def parse(self, response):
“””
ページの巡回経路を記述する関数。
:return: None
“””
options = Options()
options.add_argument(“–headless”) # ヘッドレスモードのオプションを追加
driver = webdriver.Chrome(options=options)
self.driver.get(url=”https://news.yahoo.co.jp/”) # URL を指定
# ここでログインやクリックなどの処理を挟む
response.replace(body=driver.page_source) #レスポンスオブジェクトのHTMLをseleniumのものと差し替える
news_list = response.xpath(“//body//ul[@class=’toptopics_list’]//li”)
for news in news_list:
self.logger.critical(news.xpath(“a/@href”).extract())
yield scrapy.Request(url=news.xpath(“a/@href”).extract()[0],callback=self.parse_page)
def parse_page(self, response):
item = TestprojectItem()
item[“title”] = response.xpath(“//h2[@class=’tpcNews_title’]/text()”).extract()
item[“summary”] = response.xpath(“//p[@class=’tpcNews_summary’]/text()”).extract()
yield item
[/code]
。
構成は、ページへのリクエストと巡回はseleniumにまかせて、データの抽出処理をscrapyに任せるという形です。
このように、クリックやログインなどややこしい処理はseleniumにまかせて、クリックやログイン後のHTMLを取得して、それらのHTMLを取得します。
そして、そのHTMLを取得して、それをScrapyに渡して、Scrapyの機能でデータを抽出していきます。
まとめ: Pythonを使ってスクレイピングをしよう!
スクレイピングは機械学習に限らず、自分で特定の情報のデータベースを構築したい場合などにも必要となるスキルです。
注意しなければいけない点はいくつかありますが、それを念頭においた上で効率的なデータ収集ライフを送りましょう。

